Imagine a high-tech, self-driving car that promises to drive you to your destination faster and more efficiently than any other car. The catch? The engine is a sealed black box, the controls are not accessible, and you have no idea how the car works or how it makes driving decisions. Would you enter the car?
Chances are you would not, and neither should you. As with any new technology that promises a revolutionary edge, it’s good to retain a healthy dose of skepticism for something which can be inherently complex to understand. Nevertheless, in predictive analytics and financial forecasting, the allure of Artificial Intelligence (AI) has become undeniable. AI promises to automatically harness vast amounts of data to predict your strategic KPIs and drive strategic decisions with unprecedented accuracy. While this is most certainly the future we are headed towards, the early adopters trying to use AI to help generate their forecasts are quickly realizing that behind the technological marvel, there lies a critical issue: a trust deficit in the predictions of the models.
Just as self-driving cars are statistically safer than human drivers [1], AI models usually surpass humans in predictive accuracy. However, similar to self-driving cars, without trust in these models, we can’t fully benefit from their capabilities. This gap between the promise of accurate predictions and the reality of black-box models erodes confidence in the very tools designed to help us become more confident in our financial forecasts. In this article, we delve into the importance of addressing this trust deficit and explore how we, at Predikt, are developing technology to turn this trust deficit into a surplus.
At Predikt, are developing technology to turn this trust deficit into a surplus
Accuracy is not all you need
Having trust in the predictions of AI models for financial forecasting is crucial because these forecasts directly influence critical business decisions on a day-to-day basis. Consider, for example, a retail company that uses AI to predict sales with the purpose of guiding inventory and staffing decisions. If the predictions are inaccurate, the retail company might understock or overstock inventory, resulting either in lost sales or wasteful spending. Similarly, a financial services firm might rely on AI-generated monthly revenue forecasts to allocate budgets for marketing and operations. If the firm mistakenly relies on a flawed forecast to execute a budget cut, this could disrupt its normal business operations.
The standard approach to determining whether we should trust a model’s predictions is to measure its accuracy, but this is inadequate. Why? Accuracy is typically assessed by comparing the model’s predictions to actual outcomes, which can only be done retrospectively. However, financial forecasts are inherently forward-looking and serve to guide decisions about future actions, not past events. It is well-known in the AI research community that historical accuracy provides only limited insight into how well a learned model will generalize to new, unseen situations. This means that accuracy is a necessary, but not a sufficient condition for building trust in the predictions of the AI models. On the other hand, if we were to fully understand how the model arrives at its predictions – how it processes the underlying data and identifies patterns based on its fundamental assumptions – we could more accurately assess its reliability and make better-informed decisions. Over time, such an understanding would allow us to discern when to trust the model and when to be cautious, creating a positive feedback loop where we increasingly rely on the AI for decision-making.
Getting trustworthy predictions into focus
How exactly do we transition from a trust deficit to a trust surplus? The answer lies in developing a comprehensive approach for AI model evaluation that expands beyond the traditional machine learning metrics, such as accuracy, precision, or recall. Specifically, we look at eight distinct aspects of model performance that each capture a different element of trustworthiness: robustness, accuracy, logical consistency, transparency, interpretability, confidence, interactivity, and scalability. See Figure 1 for more details. Let us delve deeper into the core ideas behind some of the most important of these aspects.
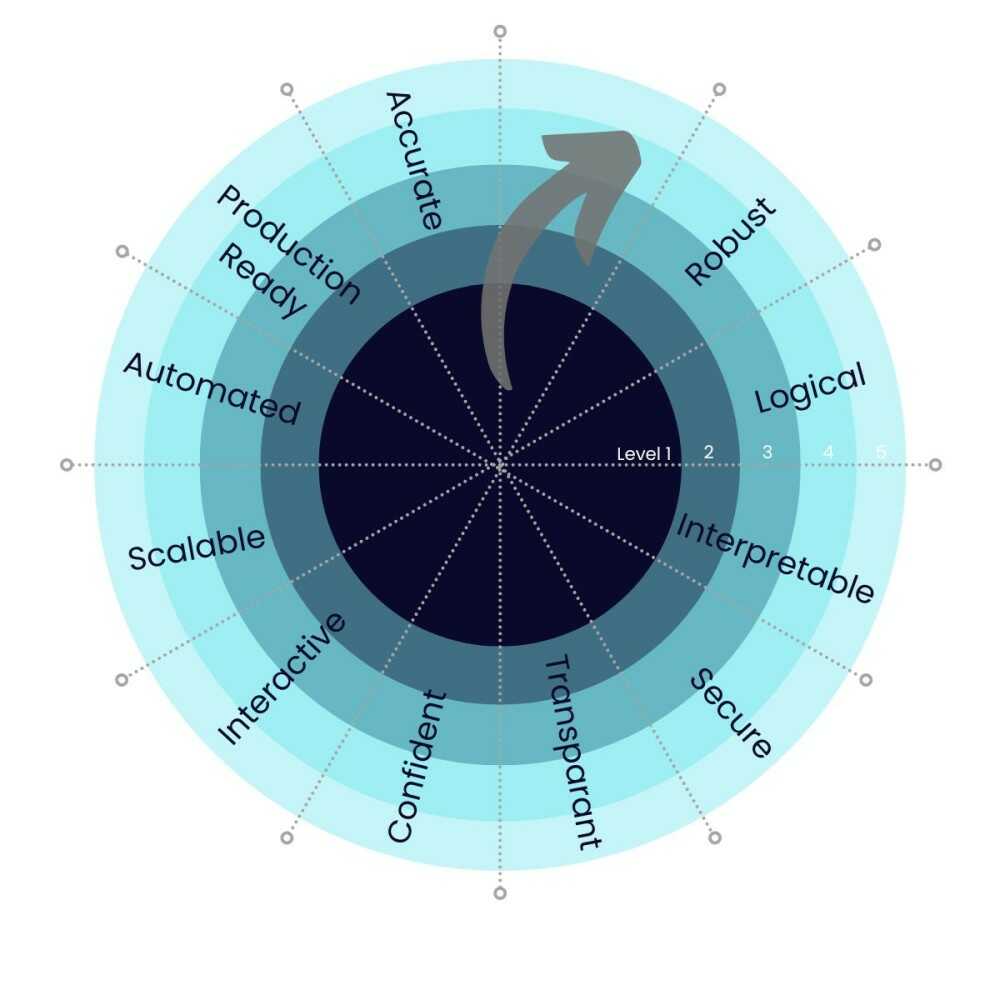
First off, robustness entails that the performance and structure of the AI models remains consistent over time, even across diverse datasets and under various conditions. While a model should change if new data (evidence) becomes available, picking up new patterns in the data and updating its predictions based on real-world outcomes, the model should not drastically change with every new data point.
AI models should be as-accurate-as-possible and strive to minimize the generalization error, but they should also be logically consistent. This means that the assumptions underlying the models, the patterns that are learned, and the predictions that are made should be consistent with how a domain expert would model the problem given sufficient time and resources. If the predictions are correct, but the model is not logical, we cannot trust it.
Each learned model should be transparent, its inner workings accessible to the people that depend on its predictions. However, while transparency is necessary, it is not enough. For example, publishing the weights of a neural network would be considered transparent, but manually sifting through millions of weights does not give you any actual understanding of what the model is doing. We need to extend the effort to make the model inherently interpretable, such that we can understand with clarity the core components of how it arrives at its predictions.
Predictions are easier to trust when the model provides a quantifiable measure of the uncertainty associated with each prediction. For example, confidence intervals indicate the range within which the true outcome is likely to fall. Wider confidence intervals signal that the model is “less sure” about its predictions.
Finally, we should be able to interact with the models, guiding and steering them into a direction that corresponds with our knowledge and our understanding of the problem. If the model is wrong, but we understand why it is wrong and we can adjust the model to reflect this, we will be significantly more comfortable trusting the model’s predictions in the future.
Building trustworthy AI models
Our core product vision revolves around systematically integrating each of the eight aspects of trustworthiness into our product offering. This requires both algorithmic improvements to the AI models generating the predictions as well as designing user experiences enabling the user to understand and interact with the models.
Building model trust begins at the outset of the machine learning pipeline with hooking up the correct data to the AI models. There is an old adage in machine learning: garbage in, garbage out. In other words: any model is only as good as the data on which it is trained. Therefore, it is paramount that the data we collect from different sources – we collect company-specific data, such as historical data and driver data, as well as external market data from various sources – are correct and validated before being fed into the AI models. One way to do this is to compute data quality scores and communicate these clearly with the business users.
When it comes to choosing the most appropriate machine learning model for a specific forecasting problem, there is often a trade-off to be made between the power of the model and its explainability. A poignant example of this are the deep-learning-based methods. Deep neural networks can be extremely capable in extracting intricate patterns from the data and making accurate predictions, the core reason as to why they are the main technology behind the recent AI boom. However, they are also notoriously difficult to interpret: you basically have no idea how the model gets its predictions. This is a no-go, as we could be easily blindsided by good historical accuracy that does not generalize to the future. On the other hand, finance is used to working with formulas as these are extremely clear. We are developing methods to rewrite learned AI models as interpretable formulas. While this limits us in the kind of models we can learn, the trade-off is well-justified.
One way of ensuring that we do not have to concede much predictive accuracy is to construct driver-based models. This has the nice side-effect of ensuring logical models that generalize effectively beyond the training data. A driver-based model is based on uncovering and quantifying the relationships between one or more drivers and the strategic KPI it tries to predict. For example, the COGS in a manufacturing company probably depend on the market prices for the raw materials going into the production process. If the price of metal goes up or down, the COGS will move correspondingly. A model that makes its predictions based on such relationships is likely to be accurate as long as the underlying relationship holds true. We developed our predictive engine in such a way that it is able to quickly learn intuitive, driver-based models from vast amounts of data.
Ultimately, we believe that user trust can only be achieved through designing collaborative AI systems in which the human and the AI work in tandem to achieve optimal outcomes. The strength of AI lies in leveraging a lot of data and identifying complex patterns, while humans are great at interpreting results, contextualizing findings, and making nuanced decisions. Let each play to their own strength. Concretely, this entails the following: developing a user interface in which the user can easily interact with the AI models and modify them, as well as constructing a machine learning algorithm that can incorporate a broad range of human feedback in its learning loop.
Advances in state-of-the-art AI research
Fortunately, we can leverage the latest AI research developments in the pursuit of our goals. In recent years, the AI community has realized the importance of building trustworthy AI models, often through painful real-world experiences where AI models malfunctioned unpredictably. This sparked several new lines of research. Explainable AI has developed a suite of tools, such as feature importance analysis or Shapley values, to explain model predictions. Most of these tools are model-agnostic, meaning they can be applied independent of the underlying machine learning model, but this makes them less powerful than baking transparency directly into the models. Concurrently, research in human-in-the-loop learning is yielding improved tools to guide and refine machine learning algorithms based on various forms of expert feedback. Adversarial machine learning explores vulnerabilities in models and methods to mitigate these vulnerabilities, driven by the recognition that models often struggle to generalize beyond their training data in critical applications. Finally, research into fairness and bias mitigation looks into how we can align the output of machine learning algorithms with our (societal) expectations.
Conclusion
If we want to leverage AI for financial forecasting, building trust in the AI models is a prerequisite, especially given the stake of the decisions that are based on such predictions. At Predikt, we believe that getting to trustworthy predictions requires simultaneously improving AI model performance along eight different faces, going from robustness and accuracy to interpretability and interactivity. Implementing this approach requires both algorithmic development and carefully designing the user experience of interacting with the models.